
EN
銀行的日常運轉高度依賴于海量信息的處理與流轉,從客戶身份認、信貸申請中的財務報表與流水,到內部運營憑證、合規(guī)審計報告——構成了信息傳遞的主要載體。然而,以上文檔往往多是非結構化或半結構化文檔,傳統(tǒng)OCR這面對這些版式多變、內容復雜度高文檔時,有著明顯的局限性。
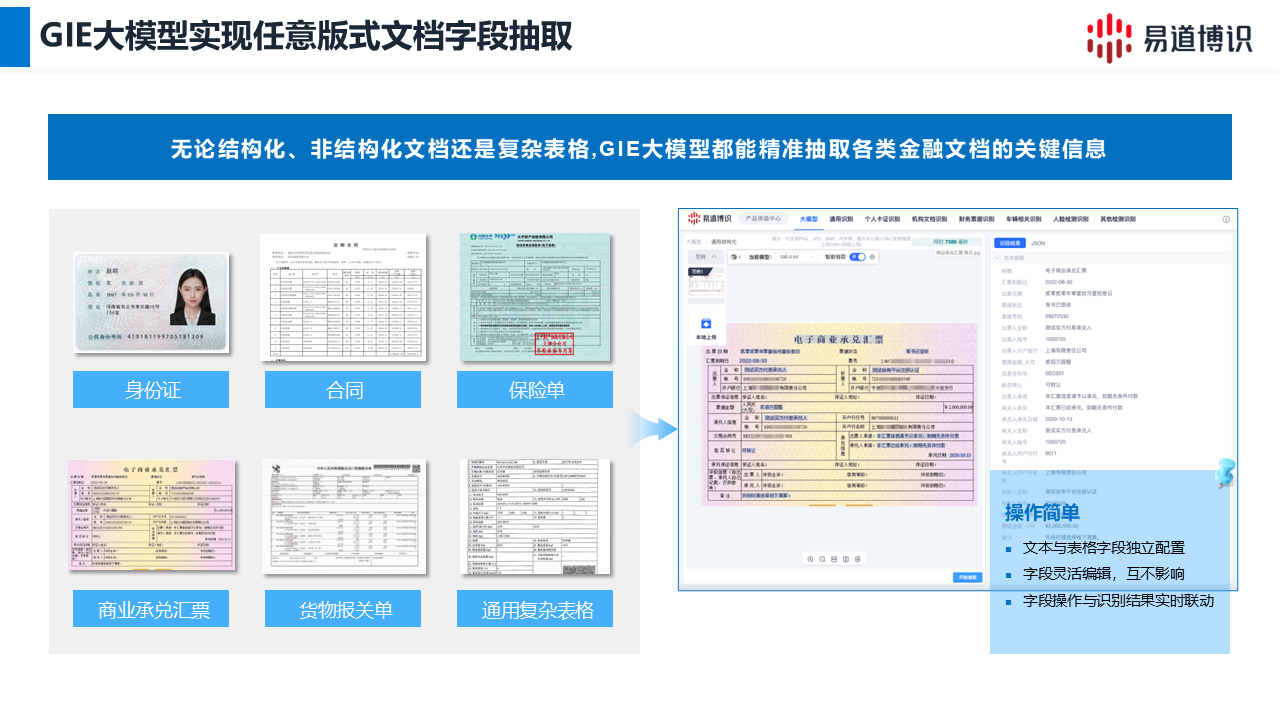
易道博識通用信息抽取(General Information Extraction, GIE)大模型,基于預訓練大模型強大的泛化與理解能力,有效識別任意版式文檔,釋放金融數(shù)據(jù)要素。
客戶準入與身份驗證(KYC):無論是線下柜面還是線上渠道,處理身份證、護照、營業(yè)執(zhí)照、銀行卡等多類證照,提取關鍵信息并完成核驗,是業(yè)務起點。人工錄入不僅效率低下、易出錯,且難以滿足高峰時段業(yè)務需求。傳統(tǒng)OCR雖能識別部分標準化證照,但對圖像質量、光照、角度變化敏感,且對新版式或非常見證件的適應性差,后臺審核壓力依然巨大。
信貸審批與風險評估:此環(huán)節(jié)涉及對銀行流水、多格式(甚至跨頁、合并單元格)財務報表(資產(chǎn)負債表、利潤表、現(xiàn)金流量表)、審計報告、抵押合同等復雜文檔的深度解析。信貸員和審批人員需從中精準提取交易對手、收支明細、財務指標、合同條款、擔保信息等關鍵數(shù)據(jù),用于評估客戶還款能力與信用風險。傳統(tǒng)技術難以有效處理復雜表格、非標格式及語義關聯(lián),導致數(shù)據(jù)提取不全、不準,大量依賴人工復核,審批周期冗長,影響業(yè)務拓展與客戶滿意度。
后臺集中運營與結算:運營中心每日需處理海量支票、匯款單、存單、各類業(yè)務申請書等憑證。傳統(tǒng)的“兩錄一校”模式人力成本高企,效率瓶頸突出,且難以根除操作風險。自動化勾挑核對因憑證版式多樣、要素復雜而進展緩慢。
合規(guī)審查與內部控制:監(jiān)管要求日趨嚴格,金融機構需從大量合同、交易記錄、內部報告中高效提取特定信息,以滿足風險排查、合規(guī)性檢查、反洗錢(AML)及審計追蹤的需求。
上述場景的共性難題在于,如何高效、準確地從海量非結構化文檔中提取結構化信息。基于模板或規(guī)則的傳統(tǒng)OCR方案,面對金融領域文檔版式靈活(尤其是客戶提供的外部文檔和不斷涌現(xiàn)的新業(yè)務表單)、內容語義復雜的特點,顯得“剛性”有余而“柔性”不足。每適配一種新模板,都需要經(jīng)歷繁瑣的數(shù)據(jù)標注、模型訓練與部署流程,維護成本高昂,難以敏捷響應業(yè)務變化。

GIE大模型通過海量金融數(shù)據(jù)訓練,復雜文檔識別效果顯著。
“Prompt即應用”的敏捷配置:GIE模型通過在海量多樣化文檔數(shù)據(jù)上進行預訓練,已內化了對各類文檔結構、版式、語言邏輯的深層理解能力,用戶無需為每種新文檔類型進行漫長的數(shù)據(jù)標注和模型訓練,僅需通過類似自然語言的“提示詞”(Prompt)或少量樣本進行配置,即可精確定義所需提取的字段(如“提取發(fā)票中的‘開票日期’和‘合計金額’”,“識別銀行流水中所有‘工資’相關的收款記錄”)。這種模式極大降低了AI應用的門檻,部署速度從數(shù)周、數(shù)月縮短至數(shù)天甚至數(shù)小時,運維成本顯著降低。
卓越的版式泛化:GIE大模型在處理復雜表格(如跨頁表格、無線表格、合并單元格、嵌套表格)、多欄排版(如研究報告、合同附件)、圖文混排(如年報、宣傳材料),乃至包含印章遮擋、水印干擾、手寫簽名、背景紋理等噪聲的文檔時,識別準確率高,更能“理解”版面布局元素間的空間關系與邏輯關聯(lián)。
適配國產(chǎn)信創(chuàng),低成本部署。GIE大模型已全面適配主流國產(chǎn)化軟硬件環(huán)境,為金融機構提供安全、合規(guī)、自主可控的智能文檔處理能力。能無縫、穩(wěn)定地運行在基于鯤鵬、飛騰、海光、龍芯等國產(chǎn)CPU,以及統(tǒng)信UOS、麒麟軟件等國產(chǎn)操作系統(tǒng)的服務器平臺上。而且可提供經(jīng)過適配優(yōu)化的軟硬一體化解決方案。
金融機構沉淀的海量文檔,實則是一座蘊藏巨大價值的數(shù)據(jù)金礦。GIE大模型正是解鎖這座金礦的關鍵鑰匙。它不僅是提升效率、降低成本的戰(zhàn)術工具,更是推動金融機構從傳統(tǒng)的、勞動密集型的“文檔處理”模式,向現(xiàn)代的、數(shù)據(jù)驅動的“業(yè)務智能”模式轉型的戰(zhàn)略引擎。
問題1: 財務報表、銀行流水等文檔格式非常多樣,甚至有跨頁、合并單元格、印章遮擋等復雜情況,GIE大模型能有效處理這些復雜金融文檔嗎?準確率和泛化能力如何?
回答:能。易道博識GIE大模型基于海量金融數(shù)據(jù)預訓練,具備強大的版式泛化能力。它能有效處理跨頁、無線框、合并單元格、嵌套表格等復雜表格,以及多欄、圖文混排、印章遮擋、手寫簽名等情況。相比傳統(tǒng)OCR,GIE不僅是“識別”,更能“理解”版面布局和語義關聯(lián),對未見過的新版式也有很好的適應性。
問題2: 金融業(yè)務變化快,經(jīng)常需要處理新的表單或憑證版式。傳統(tǒng)OCR方案每次適配新模板都需要漫長的數(shù)據(jù)標注和模型訓練,成本高、響應慢。GIE大模型在應對新文檔類型時,配置效率和成本如何?
回答:易道博識GIE大模型采用**“Prompt即應用”的敏捷配置模式。用戶無需為每種新文檔進行繁瑣的標注和訓練。僅需通過自然語言提示(Prompt),即可快速定義所需提取的字段(如“提取合同中的甲方和簽約日期”)。新業(yè)務或新版式的適配周期從過去的數(shù)周/數(shù)月縮短至數(shù)天甚至數(shù)小時。
問題3: 易道博識GIE大模型在國產(chǎn)化適配和部署方面支持情況如何?能否滿足金融機構的合規(guī)要求?
回答:易道博識GIE大模型已全面適配主流國產(chǎn)化軟硬件環(huán)境。它能夠穩(wěn)定運行在鯤鵬、飛騰、海光、龍芯等國產(chǎn)CPU,以及統(tǒng)信UOS、麒麟軟件等國產(chǎn)操作系統(tǒng)平臺上。





